日文编码系统与乱码关系之探讨
以下是生成的一篇关于“日文编码系统与乱码关系之探讨”的文章,希望对您有所帮助:
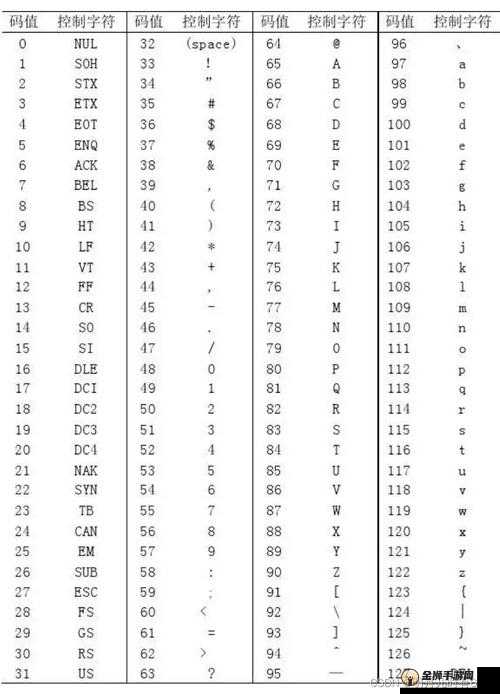
# 探索日文编码系统与乱码的神秘关系
在数字化的时代,我们与各种语言的信息交流日益频繁。而日文,作为一种独特而优美的语言,其编码系统在信息传递中扮演着至关重要的角色。我们常常会遭遇日文乱码的困扰,这不仅影响了信息的准确传达,也给我们的工作和生活带来了诸多不便。那么,日文编码系统与乱码之间究竟有着怎样千丝万缕的联系呢?让我们一同揭开这神秘的面纱。
日文编码系统的复杂性
日文编码系统之所以复杂,原因是多方面的。日文中包含了大量的汉字,这些汉字在不同的编码标准中可能有着不同的表示方式。例如,在 Shift_JIS 编码中,某些汉字的编码与在 UTF-8 编码中的编码就完全不同。
日文中还有平假名、片假名以及特殊的符号,如「々」「ゝ」等,这些字符的编码处理也需要特定的规则。
不同的操作系统和软件对日文编码的支持程度也有所差异。这就导致了在跨平台和跨软件的信息交换中,容易出现编码不兼容的问题,从而引发乱码。
常见的日文编码标准
1. Shift_JIS
Shift_JIS 是日本早期广泛使用的一种编码标准。它主要用于 Windows 操作系统的日文环境。Shift_JIS 编码的字符范围有限,对于一些不常见的汉字和特殊符号的支持不够完善,容易导致部分字符无法正确显示。
2. EUC-JP
EUC-JP 是一种扩展的日文编码标准,它能够支持更多的字符。但在实际应用中,由于其使用相对较少,与其他编码标准的兼容性问题也时有发生。
3. UTF-8
UTF-8 是一种通用的字符编码标准,被广泛应用于互联网和跨平台的信息交流中。它能够很好地支持日文以及其他多种语言,是目前解决多语言编码问题的理想选择。
乱码产生的原因
1. 编码转换错误
当日文文本在不同的编码之间进行转换时,如果转换算法不正确或者转换工具不完善,就可能导致字符的错误解读,从而产生乱码。
2. 数据源的编码错误
如果原始的日文数据本身就采用了错误的编码方式,那么在后续的处理和显示过程中,乱码就不可避免。
3. 操作系统和软件的设置问题
某些操作系统和软件的默认编码设置可能与实际的日文编码不一致,这也会导致乱码的出现。
如何避免日文乱码
1. 统一编码标准
在进行日文相关的开发和信息处理时,尽量采用统一的编码标准,如 UTF-8。这样可以减少编码转换带来的风险。
2. 正确设置操作系统和软件的编码
确保操作系统和常用软件的编码设置与所处理的日文编码相匹配。
3. 进行编码检测和转换
对于不确定编码的日文数据,可以使用专业的工具进行编码检测,并进行正确的转换。
处理日文乱码的方法
1. 尝试不同的编码解析
当遇到乱码时,可以尝试使用不同的编码标准来解析文本,看是否能够恢复正常显示。
2. 使用乱码修复工具
市面上有一些专门的乱码修复工具,可以帮助我们尝试恢复被损坏的日文编码。
3. 寻求专业帮助
如果乱码问题较为复杂,自己无法解决,可以寻求专业的技术人员或相关机构的帮助。
未来日文编码的发展趋势
随着技术的不断进步和全球化的发展,日文编码也在不断演进。未来,我们可以期待更加高效、统一和智能的编码标准出现,以更好地满足人们对多语言信息交流的需求。
随着人工智能和自然语言处理技术的发展,对于日文编码的自动识别和转换也将变得更加准确和便捷,进一步减少乱码带来的困扰。
了解日文编码系统与乱码的关系,对于我们正确处理和使用日文信息至关重要。让我们共同关注这一领域的发展,为更加畅通无阻的信息交流创造良好的条件。
以上内容仅供参考,您可以根据实际需求进行调整和修改。如果您还有其他问题,欢迎继续向我提问。